University of Westminster School of Computer Science
| 7BUIS008W Data Mining & Machine Learning | |
| Module leader | Mahmoud Aldraimli |
| Unit | Individual Coursework (Pending Moderation) |
| Weighting: | 50% |
| Qualifying mark | 40% |
| Description | Students are expected to critically engage in effectively applying and evaluating novel data mining and machine learning techniques for a specific problem domain and definitely reflect on the knowledge of how different data mining and machine learning algorithms perform in terms of biases for a given problem domain. Students are expected to methodically analyse the output of the data mining tasks and machine learning algorithms by drawing technically appropriate and sound conclusions resulting from the application of data mining and machine learning algorithms to the given problem. |
| Learning Outcomes Covered in this Assignment: | This assignment contributes towards the following Learning Outcomes (LOs):
• LO2 fully implement data mining/machine learning projects, focused on problem analysis, data pre-processing, data post-processing by choosing and implementing appropriate algorithms; • LO4 fully implement encode and test data mining and machine learning algorithms using the programming language (such as Python) and standard packages and toolkits. • LO6 perform a critical evaluation of performance metrics for data mining and machine learning algorithms for a given domain/application. |
| Handed Out: | 10th Oct 2025 |
| Due Date | 27th November 2025
Submission by 13:00 hours |
| Expected deliverables | Submit your Word document report with the answers, results and analysis on Blackboard.
And submit a Python Notebook file containing the required implemented codes and results in Python notebook format (.ipynb). |
| Method of Submission: | Electronic submission on BB via a provided link close to the submission time. |
| Type of Feedback and Due Date: | Feedback will be provided on BB, the week starting 27th December 2025 |
| BCS CRITERIA MEETING IN THIS ASSIGNMENT | • 7.1.6 Use appropriate processes
• 7.1.7 Investigate and define a problem • 7.1.8 Apply principles of supporting disciplines • 8.1.1 Systematic understanding of knowledge of the domain with depth in particular areas • 8.1.2 Comprehensive understanding of essential principles and practices • 8.2.2 Tackling a significant technical problem • 10.1.2 Comprehensive understanding of the scientific techniques |
Refer to section 4 of the “How you study” guide for undergraduate students for a clarification of how you are assessed, penalties and late submissions, what constitutes plagiarism etc.
Penalty for Late Submission
If you submit your coursework late but within 24 hours or one working day of the specified deadline, 10 marks will be deducted from the final mark as a penalty for late submission, except for work which obtains a mark in the range of 50 – 59%, in which case the mark will be capped at the pass mark (50%). If you submit your coursework more than 24 hours or more than one working day after the specified deadline, you will be given a mark of zero for the work in question unless a claim of Mitigating Circumstances has been submitted and accepted as valid.
It is recognised that, on occasion, illness or a personal crisis can mean that you fail to submit a piece of work on time. In such cases, you must inform the Campus Office in writing on a mitigating circumstances form, giving the reason for your late or non-submission. You must provide relevant documentary evidence with the form. This information will be reported to the relevant Assessment Board, which will decide whether the mark of zero shall stand. For more detailed information regarding University Assessment Regulations, please refer to the following website: http://www.westminster. ac.uk/study/current-students/resources/academicregulations
Do You Need Assignment of This Question
Coursework Description
The Real-world Problem Description
A) The Domain
The loan approval dataset is a collection of financial records and associated information used to determine individuals’ eligibility to obtain loans from a lending institution. It includes various factors such as income, employment status, loan term, and loan amount. This dataset is commonly used in machine learning and data analysis to develop models and algorithms that predict the likelihood of loan approval based on the given features. To maximise the bank’s returns, the bank can also estimate the maximum allowed loan amount for those who are approved for a loan; this practice is to maximise lending and minimise risks. There are ethical concerns about such practices, of course, around several factors like affordability. Here, we have a dataset, and we are required to model two problems with decision tree algorithms.
B) The Domain Problem
You are working for a company alongside bankers and financial risk analysts who want to automate the consumers’ loan eligibility process (real-time) based on customer details provided while filling out the online application form. These details are Gender, Marital Status, Education, Number of Dependents, Income, Loan Amount, Credit History and others. To automate this process, they have been given a problem to identify the customer segments, those who are eligible for a loan amount, so that they can specifically target these customers with maximum allowed lending values to maximise interest returns. Here, they have provided a data set.
C) Your Role as A Data Scientist
You are hired as a data scientist to work alongside a team of financial risk analysts to
1- Build predictive machine-learning models for loan approval status.
2- Build predictive machine-learning models to estimate the maximum allowed loan lending value.
The company provided you with historical records of consumer borrowers, not businesses, and their loan approval status. Also, obtained the maximum amount of approved loans.
The company relies on your work to answer the following two questions on the dataset; the key objective is to create a new, predictive tool powered by a machine learning model to assist the company in automating loan approvals to enhance productivity and client service. The Questions are:
a) Does your machine learning modelling have the potential to automate the loan approval decisions for the company?
b) For loan-approved clients, can your machine learning models offer a reliable estimate of the maximum lending value on an approved loan?
D) Your Dataset
This dataset was obtained from multiple lenders for November 2024; some of the values may have been manually or electronically recorded. The aggregated dataset provides information on the clients’ applications. The dataset contains the following attributes:
Table.1 Data Dictionary
| Attribute | Description |
| ID | Unique identification for each consumer client |
| Sex | The applicant’s sex Male (M) or Female (F) |
| Age | A client’s age in years |
| Education Qualifications | Highest level of formal certifications a client has completed. |
| Income | A client’s total annual gross earnings |
| Home Ownership | The status of the client’s residential property |
| Employment Length | A client’s years of employment |
| Loan Intent | The purpose of borrowing |
| Loan Amount | The value of requested borrowing by the client in GBP |
| Loan Interest Rate | The percentage cost of borrowing money |
| Loan-to-Income Ratio (LTI) | LTI ratio is a loan lending metric that divides the loan amount by the borrower’s gross annual earnings. |
| Payment Default on File | A default is recorded on your credit report indicating missed payments |
| Credit History Length | The average age of all your debit and credit accounts. |
| Loan Approval Status | Indicator of the client’s application acceptance or rejection for the requested loan. |
| Maximum Loan Amount | The largest sum of money a lender is willing to provide to an approved borrower in GBP. |
| Credit Application Acceptance | A lender has agreed to offer you a loan (Yes: 0 and No:1) |
Note: To comply with GDPR regulations, the data was anonymised, and the clients can no longer be contacted for information.
Your Coursework Tasks & Framework
As a data scientist, you are a logician, a mathematician, a technician, and an analyst, and you need the financial experts to understand your analyses. Lenders are usually busy individuals, and they don’t have all the time in the world. One essential skill that you must adhere to is to be concise and straight to the point. Focus on the answers needed for each task and provide just enough words for the answer only. There is no need to provide lengthy descriptions of algorithms and methods unless you are asked to do.
Also, they are only interested in assessing your interpretation of the modelling results, so you MUST NOT paste any Python code in this report unless specifically asked to so. You will receive a separate link to submit your code as a Python notebook file (mandatory). ipynb extension. Your data mining tasks will be aligned with the popular CRISP-DM methodology phases but without the deployment phase (see Figure 5).
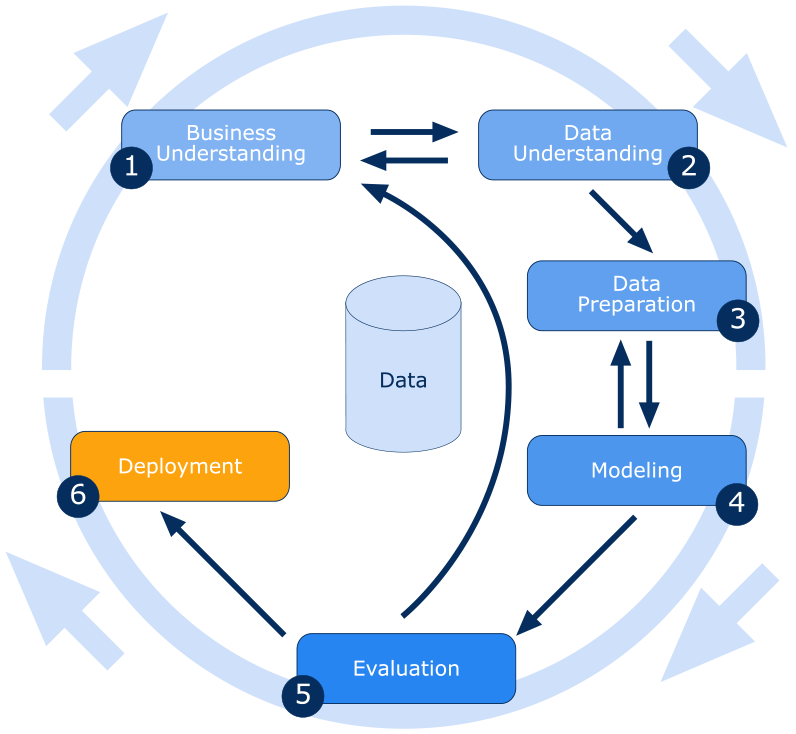
Fig.2 CRISP-DM Phases
⚠️ Important Note: You must answer each task chronologically and use the questions as headers⚠️
Buy Answer of This Assessment & Raise Your Grades
PART (A) Loan Approval Status Prediction [65 MARKS]
For Research Question A
Does your machine learning modelling have the potential to predict those who would be accepted or rejected for a loan?
Task (1) – Domain Understanding: Classification
[Total 6 Marks]
The financial risk analysts decided that classification modelling is required. Indicate in the table below for each of the listed variables in your data which ones you should RETAIN and can be included in the classification modelling of loan approval status, and the variables you should DROP (REMOVE). Justify your decision logically and/or by research (for any research, include in-text citation using the Harvard style)
| Variable Name | Retain or Drop | Brief justification for retention or dropping |
| ID | ||
| Sex | ||
| Age | ||
| Education Qualifications | ||
| Income | ||
| Home Ownership | ||
| Employment Length | ||
| Loan Intent | ||
| Loan Amount | ||
| Loan Interest Rate | ||
| Loan-to-Income Ratio (LTI) | ||
| Payment Default on File | ||
| Credit History Length | ||
| Loan Approval Status | ||
| Maximum Loan Amount | ||
| Credit Application Acceptance |
Task (2) – Data Understanding: Producing Your Experimental Design
[Total 3 Marks]
From your Python notebook, for your RETAINED input variables and your class “target” variable, produce a basic statistical description and variable scale type. Plot the distribution of your target variable. (Paste screenshots of code OUTPUTS ONLY for evidence).
Task (3) – Data Preparation: Cleaning and Transforming your data
[Total 16 Marks]
a) Investigate any issues in your retained dataset and the possible variables. Based on the issues you find in your data, suggest a suitable method to mitigate each of these issues and provide your justification for using each method. Use the table below to organise your findings, add more rows if needed: [8 Marks]
| Variable Name | Issue description | Proposed mitigation | Justification for used mitigation |
| ⋮ | ⋮ | ⋮ | ⋮ |
b) With the aid of Python packages and a notebook, implement your suggested mitigations of issues in Task (3.a) , and show evidence of implementing your suggested solutions to the problems you identified for your dataset in (Task 3. a). For evidence, use screenshots of code OUTPUTS ONLY. Indicate and annotate in your screenshots which issue was resolved in each screenshot provided. Show screenshots of code outputs before and after implementing your solution. [8 Marks]
Task (4) – Modelling: Create Predictive Classification Models
[Total 10 Marks]
a) From the classification algorithms which you learned in the module, four different algorithms were selected: Logistic Regression (LR), Random Forest (RF) and Naïve Bayes (NB). These algorithms are a mix of parametric and non-parametric algorithms. List down the type of each algorithm (parametric vs non-parametric), name any learnable parameters, and list any possible hyperparameters for each algorithm which you may want to consider tuning. Note the Python package and module for importing each algorithm. Again, organise your answer in a table as before. See below: [6 Marks]
| Algorithm Name | Algorithm Type | Learnable Parameters | Some Possible Hyperparameters | Imported Python package to use the algorithm |
| NB | ||||
| LR | ||||
| RF |
b) With the aid of the Python packages, use the training–test split approach with your retained applicable categorical input features only and the class output feature to build your predictive classification models. [4 Marks]
i. Screenshot the list of all feature names used for building your classification models and the corresponding data shape function output.
ii. In less than 100 words, research and justify your choice of the training-test split ratio and provide an in-text citation.
iii. In less than 100 words, discuss the overall purpose of using a training-test approach in contrast to the use of validation sets in K-fold cross-validation and describe the case/s when to apply each of those approaches.
iv. Provide as evidence the code line from your source code that ensures that all models were tested on the same test dataset, also ensure that the labels ratio of Loan Approved to Declined Status is the same in both training and test sets.
Task (5) – Evaluation: How good are your models
[Total 30 Marks]
Your Financial analysts provided the following success criteria to guide you when evaluating your models.
“When evaluating your model’s performance, which addresses your first research question (a). The model is expected to misclassify clients’ applications. Thus, the model should aim to predict the “Reject” status of subjects for as many as possible to decrease the risk of future defaulted loan payments. However, the model should demonstrate that its high “Reject” prediction rate is mainly due to a larger portion of correctly detected (predicted) rejected loan applications.”
a) With the aid of Python packages, paste the test confusion matrix for each trained model as screenshots from the output of your Python code. [3 marks]
b) Five different classification evaluation metrics are noted. Paste each model’s test performance results. State which evaluation metric/metrics to “USE or “NOT USE” to closely interpret the above success criteria. For justification, explain how closely your choice of “USE” or “DO NOT USE” for a metric interprets the given success criteria. With the aid of Python packages, document the TEST SCORES for each built model. [15 marks]
| Metrics | USE or DO NOT USE | Justification in relation to the success criteria | Model Name | Test Score |
| Accuracy | NB | |||
| LR | ||||
| Rf | ||||
| Recall | NB | |||
| LR | ||||
| RF | ||||
| Precision | NB | |||
| LR | ||||
| RF | ||||
| F-Score | NB | |||
| LR | ||||
| RF | ||||
| AUC-ROC | NB | |||
| LR | ||||
| RF |
c) Suggest a single best classification model based on the ‘USED’ performance metrics scores you identified in (Task 5. b). Briefly describe how well your best model satisfies the needs of the financial risk professionals. [2 marks]
d) Investigated with evidence to establish whether your selected best model is a good fit, underfit or overfit.
[3 marks]
e) To enhance your selected best model/s performance, tune some of its possible hyperparameters, which you indicated in (Task 4. a) for that specific algorithm. With the aid of Python packages, retrain the algorithm again with GridSearchCV [5 marks]
i. Indicate the number of cross-validation K folds used (paste evidence from your Python notebook).
ii. For the newly tuned model, document the estimated best hyperparameters against the originally used hyperparameters
iii. Present the test confusion matrix for the best models before and after tuning.
iv. Calculate and document the new score/s of the “USED” performance metric/s of your choice to interpret the success criteria identified in (Task 5.b) before and after tuning.
v. Use your observations to comment on whether the tuning of hyperparameters of your best model improved its positive predictive ability in line with the success criteria.
f) Based on your best model, draft an answer for the research question, criticise your best-performing model, and state any limitations you may have identified. Research and try to explain why your selected algorithm overtook all other models in no more than 100 words. State any ethical issues your model may raise if used to decide loan approval. [2 Marks]
__________________________________________________
Are You Looking for Answer of This Assignment or Essay
PART (B) Maximum Loan Amount Prediction [35 Marks]
For Research Question B
For loan-approved clients, can your machine learning modelling offer a reliable estimate of the maximum offered loan amount?
Task (1) – Domain Understanding: Regression
[Total 2 Marks]
The analysts decided that regression modelling is required. Using Python functions, show the dimensions of your data subset that you will RETAIN for this regression modelling problem. Using Python functions, list the names of the features that you intend to use for this regression modelling from Table 1.
Task (2) – Data Understanding: Producing Your Experimental Design
[Total 5 Marks]
From your Python notebook, plot the distribution for your RETAINED input variables and your “target” variable (Paste screenshots of code OUTPUTS ONLY “the plots” for evidence).
Task (3) – Data Preprocessing: Transforming your data
[Total 5 Marks]
a) By looking at the dataset, establish whether there is a need for scaling your dataset attributes. Explain with evidence from your Python code output the reasoning behind your recommendation. [2 marks]
b) In general, when applying scaling to any dataset for regression modelling, would you scale the input features only, the target feature only, or all features? In less than 150 words, briefly justify your answer and include an in-text citation where appropriate. [3 marks]
Task (4) – Modelling: Build Predictive Regression Models
[Total 7 Marks]
a) From the regression algorithms which you learned in the module, the analysts decided on the use of a Decision Tree Regression (DT) In less than 50 words, explain the added benefit of using a DT regressor for this financial prediction problem. [2 marks]
b) With the aid of the Python packages, you will use a training–test split of 80:20 to build and test two DT regression models, Model 1 & Model 2. The first DT model (DT1) uses the numeric retained features only, and the second model (DT2) uses all your retained features:
i. From your Python notebook, insert in your report, provide as evidence the code line from your source code that ensures reproducibility of your training-test sampling. [1 mark]
ii. Using Python packages, show from your code output the dimensions of your training and test subsets used for each model. List the subset of feature names used for Model 1 and Model 2. [4 marks]
Task (5) – Evaluation: How good are your models
[Total 16 Marks]
Your risk analysts provided the following success criteria to guide you when evaluating your models.
“When evaluating both models’ performances, which addresses your question (b), the model is expected to make some errors in estimating the maximum load amount offered on approved applications. However, the selected model out of the two built models should have input features that are better at explaining the recorded values of the maximum loan amount”.
a) Three different regression evaluation metrics are noted. State which evaluation metric/metrics to USE or NOT USE to interpret the above success criteria closely. Justify your choice of USE or DO NOT USE. With the aid of Python packages, document the TEST SCORES for each built model. [6 marks]
| Metrics | USE or DO NOT USE | Justification in relation to the success criteria | Model Name | Test Score |
| MSE | DT1 | |||
| DT2 | ||||
| MAE | DT1 | |||
| DT2 | ||||
| R-Square | DT1 | |||
| DT2 |
b) Describe any caveats to your selected performance metric, assessing the ability of your model to meet the success criteria. [2 marks]
c) Suggest a single best regression model (DT1 or DT2) based on the ‘USED’ performance metrics scores you identified in (Task 5. b). Briefly describe how well your selected best model satisfies the needs of the finance professionals. [2 marks]
d) The Finance risk analysts aim to explain the best model’s decision of estimated maximum loan amounts offered to the client. Therefore, rebuild your best model while performing pre-pruning (4 levels limit) to ease the interpretation of your best model’s decision. Plot the pruned tree and paste it here from your Python notebook results. Describe with evidence if there were any performance advantages or disadvantages of pruning your best tree model. [4 marks]
e) Using your pruned model, predict the maximum loan amount offered to client 60256 whose attributes values are the following: [2 marks]
| Variable Name | Value |
| ID | 60256 |
| Sex | F |
| Age | 56 Years old |
| Education Qualifications | Unknown |
| Income | 57,000 |
| Home Ownership | Rent |
| Employment Length | 15 |
| Loan Intent | Medical |
| Loan Amount | 25700 |
| Loan Interest Rate | 23% |
| Loan-to-Income Ratio (LTI) | 10% |
| Payment Default on File | No |
| Credit History Length | 35 |
| Loan Approval Status | Approved |
| Maximum Loan Amount | ? |
| Credit Application Acceptance | 0 |
END OF COURSEWORK TASKS
Critical notes about your coursework submission
- Critical: Do not share/show your code, report, or results with any other student for any reason. Past students who shared their work with others were investigated for collusion by an Academic Misconduct Panel and awarded a zero mark.
- Submit your Python notebook using the given submission link for the Python code; ensure it is in ipynb Failing to submit your Python notebook will result in a zero mark for the coursework. Your Python code and notebook will be used to verify your coursework outputs; discrepancies between the report and notebook can result in full marks deductions for a question.
- This coursework is limited to a maximum of 23 pages. The minimum font is Arial size 10 single-spaced. A minimum of 1-inch page margins. Exceeding the 23-page limit or not complying with the specified font size can result in a 15% penalty deduction from your report’s mark.
- Use the question numbers as headers; answer the tasks in the correct order. You do not need to copy the full question; you may summarise a new header from the question, but that is unimportant. Your answers must map to each question’s number and task in the correct order. Otherwise, this may lead to a significant delay in marking your work and the potential of missing out on marks lost between the lines.
- There is no need to go on a new venture with coding in Python! Follow the process of code reuse. For those new to Python, all the Python code you need is given in your tutorial documents and solution Python notebooks. You only need to stitch it together from different tutorials to get the required outputs. However, I won’t stop you from going on a venture with new Python coding.
- Some of the submissions may be invited for a 20-minute viva. So be prepared to explain your code and findings should you have been invited for one. Failing to attend the viva can result in a zero grade.
Do You Need Assignment of This Question
The post 7BUIS008W Data Mining & Machine Learning Individual Coursework appeared first on Students Assignment Help UK.